ИИ выдумывает источники: как не завалить диплом из-за этой ошибки
Преподаватели уже знают, как выглядит список литературы от ИИ. Рассказываем, что их настораживает и как этого избежать
Как работают языковые модели
ChatGPT и другие нейросети — это продвинутые версии автодополнения текста, вроде Т9 в телефоне. Система обучается на миллиардах документов и запоминает паттерны: какие слова обычно идут после предыдущих, как строятся предложения, как выглядят научные статьи.
Например, когда вы просите написать параграф про экономику, алгоритм не ищет информацию в интернете — он конструирует текст, который статистически похож на материалы из обучающей выборки.
ИИ понимает, что библиография выглядит примерно так: «Иванов И. И. Название книги. — М.: Издательство, 2020. — 300 с.». Он видел тысячи похожих записей и научился их воспроизводить. Но модель не знает, какие именно книги существуют — она просто комбинирует элементы так, чтобы получилось правдоподобно.
Что такое галлюцинации
Галлюцинации — это уверенная выдумка. Термин пришел из психиатрии, где означает восприятие того, чего не существует. В контексте ИИ так называют ситуацию, когда алгоритм создает информацию, которой нет в реальности, но подает ее как достоверный факт. ChatGPT с полной убежденностью сообщит, что существует книга «Современные методы анализа данных» автора Петрова А. В., хотя ни публикации, ни автора не существует.
Почему галлюцинации неизбежны. Языковая модель не различает правду и вымысел — она подбирает слова, которые кажутся уместными. Столкнувшись с пробелом в данных или запросом по малоизученной теме, алгоритм заполняет пустоты собственными конструкциями. Система обучена давать связные ответы, а не признавать незнание, поэтому додумывает недостающие фрагменты.
ИИ делает ошибочные выводы из-за неожиданных ошибок в нейронных связях, которые они сформировали на этапе обучения. Другими словами, они совершают ошибки, потому что ничего не знают.
Что говорят научные исследования
Ученые из университета Дикина поручили GPT-4o написать шесть обзоров литературы по темам психического здоровья. Они обнаружили, что почти 20% из 176 цитат были полностью сфабрикованы. Среди 141 реальной цитаты 45,4% содержали неправильные даты и неверные номера страниц. В целом только 43,8% — 77 из 176 цитат — были настоящими.
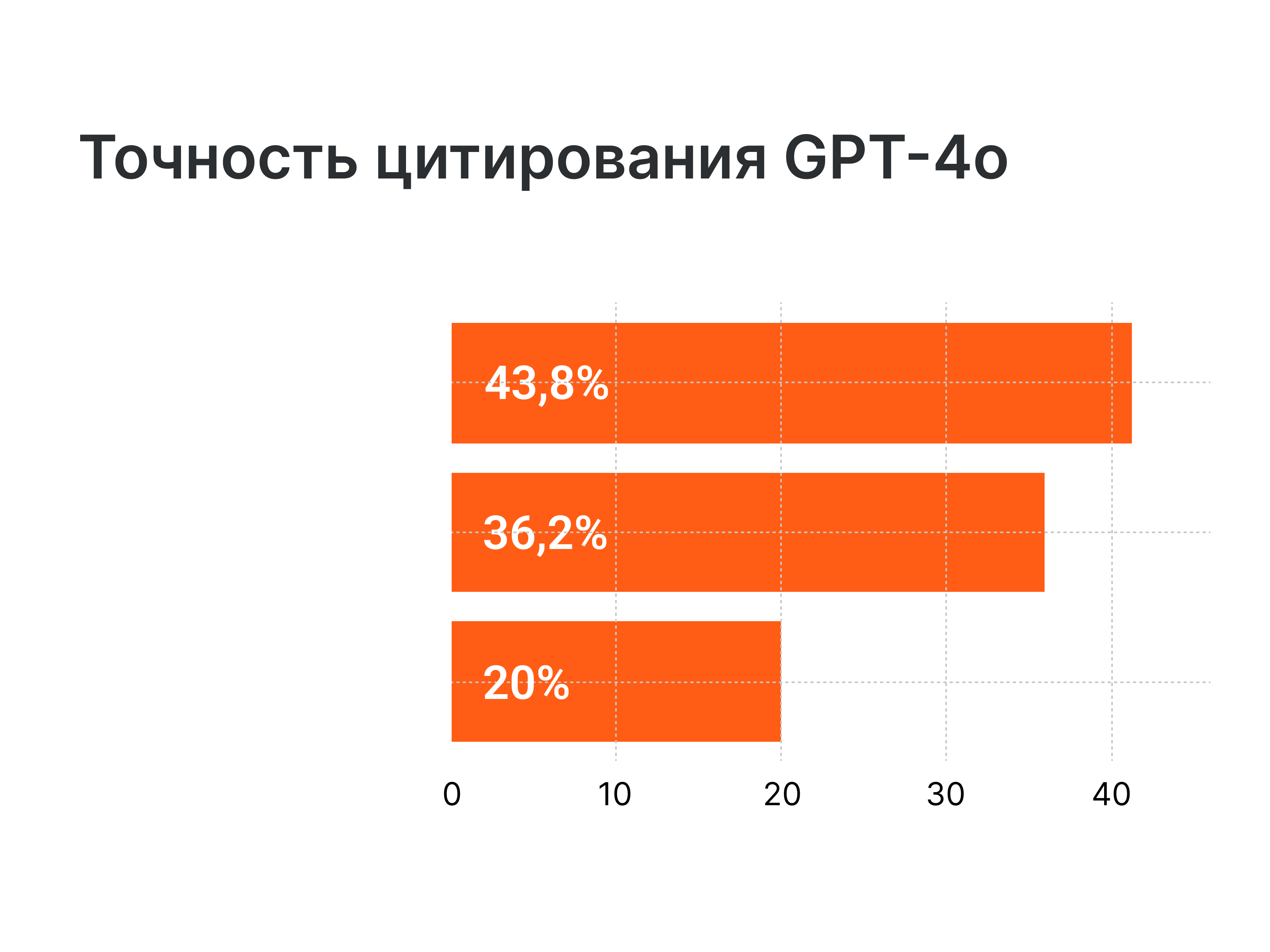
Сфабрикованные цитаты не были явно фальшивыми. Когда GPT-4o предоставил предполагаемый DOI (уникальную ссылку, известную как «идентификатор цифрового объекта») для сфабрикованной цитаты (33 из 35 сфабрикованных источников включали DOI), 64% ссылались на фактически опубликованные статьи по совершенно несвязанным темам.
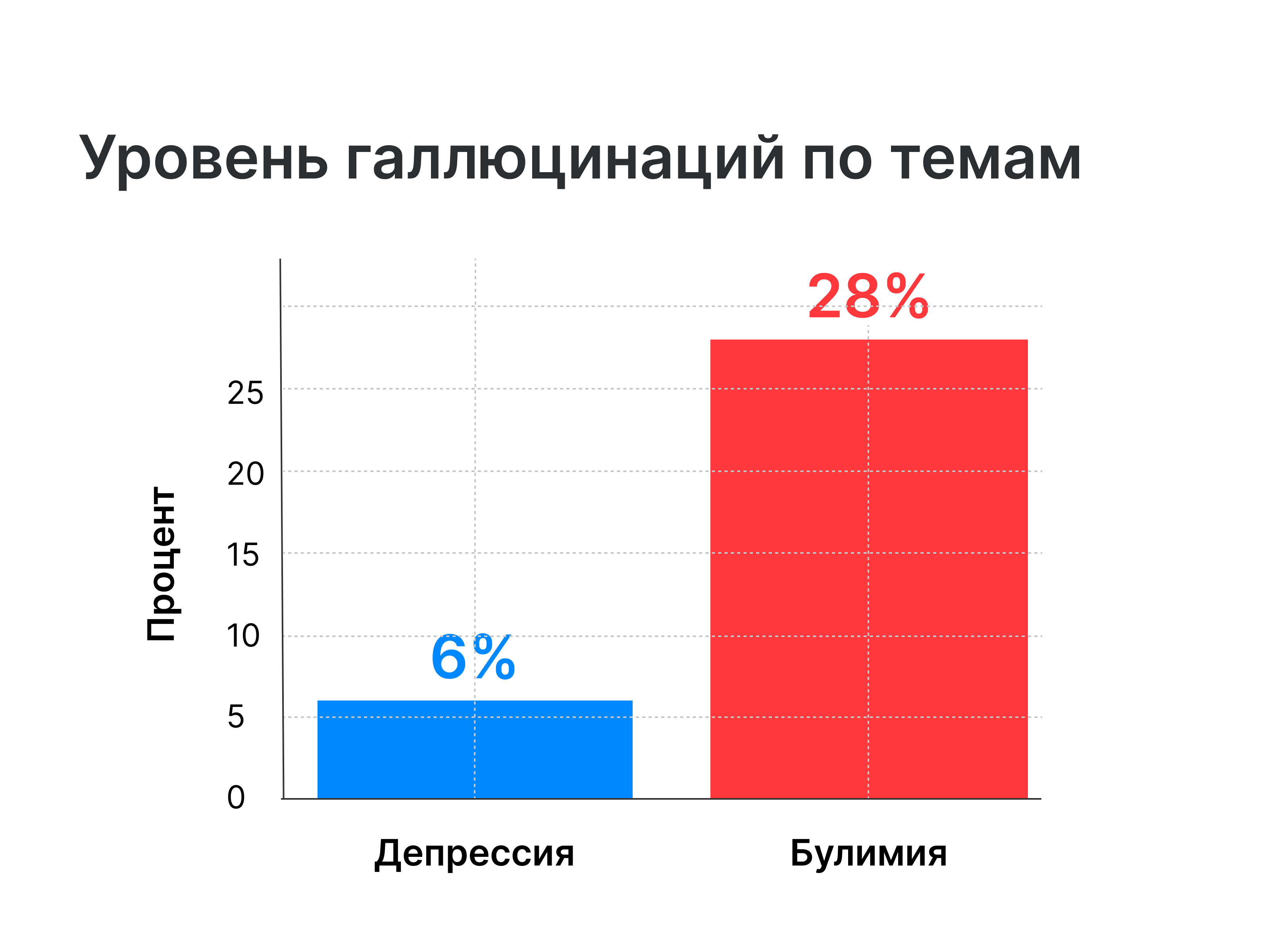
Точность цитирования GPT-4o сильно различалась от того, о каком расстройстве он писал. Только 6% цитат про депрессивное расстройство были галлюцинациями, но когда темой была булимия, уровень галлюцинаций повысился до 28%.
Почему галлюцинации опасны для студенческих работ
Преподаватели проверяют источники — это часть их работы. Научный руководитель или рецензент открывает список литературы, выбирает несколько позиций и пытается их найти: вбивает название в Google, ищет автора в elibrary, переходит по ссылкам. Один несуществующий источник выглядит как звоночек, три-четыре выдуманных книги — и студента отчитывают.
Риск не только в том, что работу не примут. Если выяснится, что студент сознательно указал ненастоящие источники, это может обернуться более серьезными последствиями. Преподаватели понимают разницу между случайной ошибкой в оформлении и списком литературы, где половина книг не существует.
Типичные ошибки ИИ в источниках
Полностью выдуманные источники
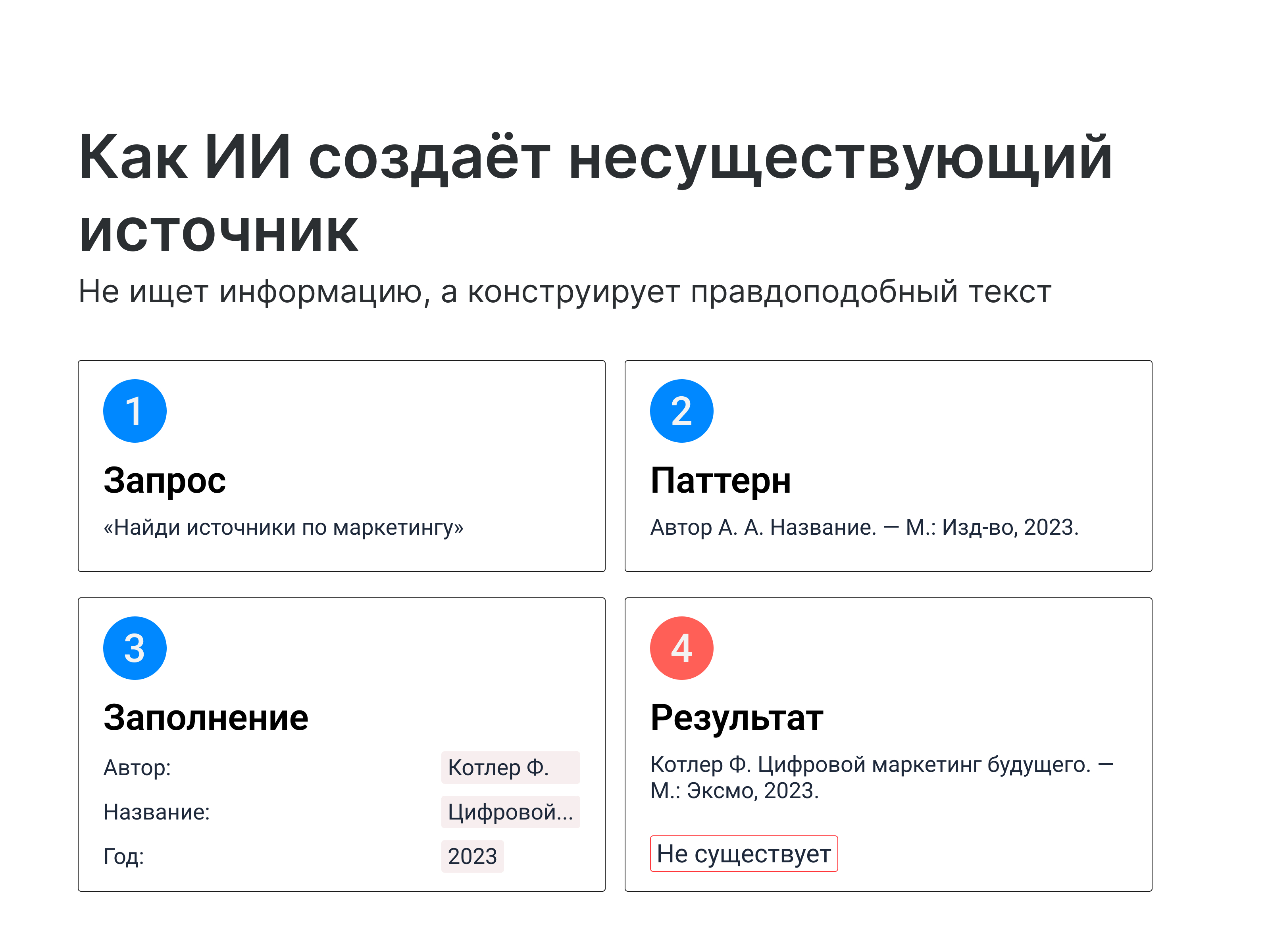
Несуществующие книги. Например, студент просит ChatGPT составить список литературы по теме маркетинга. Нейросеть генерирует книгу «Котлер Ф. Цифровой маркетинг будущего. — М.: Эксмо, 2023. — 450 с.» — увы, хотя название звучит убедительно, а Котлер действительно известный специалист, такой публикации он не выпускал.
Несуществующие журналы и статьи. Или пример с научными журналами: иногда в списке появляется статья «Инновации в управлении персоналом» из журнала «Вестник современного менеджмента» — что статья, что журнал выдуманы, хотя название звучит по-умному, в духе научной лексики.
Выдуманные конференции. Нейросеть ссылается на материалы конференции, которой никогда не было. «Материалы III Международной научно-практической конференции «Цифровая трансформация бизнеса»» звучит солидно, но при проверке выясняется, что такая конференция не проводилась — ИИ собрал название из стандартных формулировок.
Мертвые ссылки. Еще чаще бывает, когда алгоритм присылает ненастоящие URL вроде https://journal-management.ru/articles/2023/innovation.pdf. Пусть адрес кажется реальным, студенту не стоит обманываться: если перейти по ссылке, там ничего не будет. Иногда домен существует, но конкретной страницы с указанным материалом там никогда не было.
Путаница из реальных источников
Перепутанные авторы. Книга действительно существует, но ИИ приписывает ее другому автору. «Основы маркетинга» Филипа Котлера нейросеть может указать как работу Питера Друкера — да, они оба известны как специалисты по маркетингу и менеджменту, но автор книги совсем другой.
Смешение разных источников. Нейросеть берет автора из одной книги, название из другой, а издательство из третьей. В результате получается библиографическая запись, где каждый элемент реален, но вместе они никогда не существовали — как собрать автомобиль из деталей от разных марок.
Неверные данные издания. Книга существует, автор правильный, название тоже верное, но город издания указан неправильно. «СПб.: Питер» вместо «М.: АСТ» — преподаватель проверяет по РГБ и видит несоответствие.
Ошибки в библиографических данных
Неверные годы издания. ИИ указывает свежую дату для книги, которая вышла давно, или, наоборот — ставит старый год для недавней публикации. Книга 2010 года вдруг оказывается изданной в 2023-м, или источник помечен как опубликованный за несколько лет до того, как автор начал исследование.
Проблемы с ISBN и DOI. Нейросеть генерирует эти идентификаторы по принципу «выглядит правдоподобно» — набор цифр похож на настоящий, но при проверке оказывается, что такого кода не существует. В лучшем случае этот номер принадлежит совершенно другому источнику.
Ошибки в оформлении по ГОСТу. Элементы библиографии стоят в неправильном порядке, отсутствуют обязательные поля вроде количества страниц или тома. Нейросеть знает, что нужны точки и тире, но не понимает строгих правил их расстановки — получается «почти по ГОСТу», но с ошибками.
Дублирование источников. Один и тот же источник появляется в списке литературы дважды, но под разными формулировками. Сначала «Смирнов А. В.», потом «Смирнов Андрей Владимирович», и нейросеть считает это разными авторами.
Проблемы с актуальностью и релевантностью
Устаревшие или отмененные НПА. Для юристов особенно опасно — нейросеть ссылается на закон, который давно утратил силу или был существенно изменен. Студент пишет диплом по трудовому праву и опирается на редакцию Трудового кодекса десятилетней давности, хотя положения уже не действуют.
Источники не по теме. ИИ подбирает реальные книги, но они не имеют отношения к теме работы. В дипломе о цифровом маркетинге появляется монография по истории древнего Рима — просто потому, что нейросеть нашла совпадение в одном из слов запроса.
Ошибки в транслитерации. При работе с иностранными источниками ИИ путает системы транслитерации или переводит имена авторов неправильно. Фамилию Schmidt нейросеть может передать как «Смидт», «Шмидт» или «Сцмит» — найти оригинальную статью по такой записи невозможно.
Ошибки в логике
Хронологические нарушения. Нейросеть может указать, что автор опубликовал статью в 2015 году, хотя по открытым источникам он родился только в 2000-м. Или диссертация датирована 2020 годом, но автор умер в 2018-м — ИИ просто не сопоставляет даты с биографией.
Как проверить источники
Искать по названию книги в Google или Яндексе. Если это актуальный источник, чаще всего он отобразится в первых результатах выдачи, либо появится ссылка на обложку книги или аннотацию на сайтах издательств и библиотек.
Проверять автора в научных базах. Чтобы проверить, что автор публикации живой человек, рекомендуем воспользоваться научными базами данных: например, eLibrary, CyberLeninka, Google Scholar. Там можно найти публикации конкретного ученого и список его работ. Если автора в этих базах нет или у него нет публикаций по теме, нужно насторожиться.
Проверять ссылки — переходить и смотреть, существует ли статья. Если в работе есть прямые ссылки на статьи (URL, DOI), перейдите по ним и проверьте, на самом ли деле ссылка ведет к нужному источнику. Также нужно проверить корректность DOI и ISBN через специальные сервисы CrossRef, ISBNdb, DOI.org.
Сверять год издания с биографией автора. Важный пункт для проверки адекватности ссылки — сопоставить год публикации с биографией автора. Если работа вышла после смерти исследователя или с датой, которая несовместима с его временем активности, это может указывать на ошибку или выдумку источника. Также стоит понимать, что устаревшие по дате издания документы могут быть заменены более актуальными, особенно в быстро развивающихся областях знаний.
Как избежать проблем с источниками
Проверяйте вручную
Плюсы: источники точно настоящие, так как вы сами их нашли. Полное соответствие требованиям академичности.
Минусы: долго и нужно знать, где искать (в библиотечных каталогах, справочниках, специализированных базах данных; нужно знания, где искать надежные источники; нужно лично прочитать и проанализировать каждый источник.
Используйте ИИ с доступом к интернету
Плюсы: ИИ может искать реальные источники в интернете и академических базах; показывает кликабельные ссылки на оригиналы; экономит время на сборку первоначального списка.
Минусы: все равно нужна обязательная проверка каждой ссылки; Perplexity ошибается примерно в одном из трех случаев; нужно кликать по каждой ссылке и открывать оригинальный источник; не гарантирует полноту и точность всех элементов ссылки.
Примеры инструментов:
- ChatGPT с плагинами Web Search — может искать реальные источники через Bing.
- Perplexity AI — специализирован на поиске с цитированием, показывает номерованные ссылки.
- Elicit — автоматизирует литературные обзоры из peer-reviewed источников.
- ResearchRabbit — поиск через найденную публикацию.
- Semantic Scholar — AI-поисковик с анализом миллионов статей.
- Litmaps — визуализирует сети цитирования и отслеживает релевантные работы.
Что делать, если уже написал работу с выдуманными источниками
1. Прогнать весь список литературы через проверку. Пройдитесь по каждому источнику: вбейте название и автора в Google или Яндекс, проверьте через Google Scholar, eLibrary, CyberLeninka, CrossRef (для DOI). Все, что не находится ни в одной базе, открывается «пустой» страницей или не бьется по ключевым данным (автор, год, журнал, том, номер), нужно считать проблемным. Лучше сделать отдельную пометку напротив каждого сомнительного источника.
2. Заменить выдуманные источники реальными. Для каждой «фантомной» ссылки найдите реальную публикацию по той же теме: учебник, монографию, статью из рецензируемого журнала, главу из сборника. Ищите по ключевым словам, которые вы обсуждаете в тексте работы, а не по выдуманному названию. Важно, чтобы новый источник действительно подтверждал мысль, для которой вы ставите ссылку.
3. Перелинковать ссылки в тексте. После замены списка литературы нужно обновить все ссылки в тексте: номера источников, автор-год, сноски. Если вы удалили или добавили несколько позиций, нумерация «поедет», и придется пройтись по работе и аккуратно синхронизировать текст со списком литературы.
4. Убедиться, что оформление по ГОСТу корректное. Когда очистите дипломную от выдуманных источников, проверьте чисто техническое оформление:
- Порядок элементов (автор, название, место издания, издательство, год, страницы).
- Наличие обязательных полей,
- Правильные сокращения,
- Единый стиль для всех записей.
Сверьтесь с актуальной версией ГОСТа или методичкой вуза. Приведите все записи к единому стандарту — это последний шаг, который превращает «починенный» список литературы в аккуратный.