
Как ИИ помогает предупреждать уход сотрудников
Выявить тренды и сделать прогнозы сегодня можно с помощью машинного обучения. Как это сделать, расскажем в кейсе
Задача — выявить скрытые взаимосвязи и определить ключевые факторы, которые мотивируют сотрудников продолжать сотрудничество с компанией, с помощью ML-технологии.
Причина — Часто бизнесу не очевидно, какие факторы влияют на решение покинуть компанию и какие превентивные действия можно предпринять и отреагировать на опережение, поскольку затраты на поиск, привлечение, адаптацию и обучение новых специалистов могут доходить до 100% их годового оклада.
В условиях высокой конкуренции на рынке труда и постоянных изменений потребностей бизнеса важным конкурентным преимуществом компании становится способность прогнозировать риски ухода сотрудников. Какие факторы чаще других влияют на решение покинуть организацию и кто находится в зоне риска? Бизнесу важно знать ответы на эти вопросы, чтобы реагировать на опережение, поскольку затраты на поиск, привлечение, адаптацию и обучение новых специалистов могут доходить до 100% их годового оклада.
Выявить тренды и сделать прогнозы сегодня можно с помощью машинного обучения (Machine Learning, далее — ML). В этой статье рассмотрим кейс применения ML-технологий в SimbirSoft для прогнозирования увольнений сотрудников. Поделимся выявленными закономерностями, результатами тестирования модели и ключевыми выводами. Статья будет полезна руководителям и собственникам бизнеса, HR-специалистам, а также лицам, заинтересованным в улучшении HR-процессов компании с применением технологий ИИ.
Предыстория
Компании по всему миру активно внедряют передовые технологии для автоматизации процессов, улучшения условий труда и повышения вовлеченности сотрудников. Как IT-компания мы постоянно внедряем технологические решения, которые помогают оптимизировать HR-процессы. Например, процедуры найма у нас полностью автоматизированы и реализованы в собственной HRM-системе MakeTalents. Этот инструмент позволяет хранить всю необходимую информацию в одном месте, эффективно собирать данные и оценивать результаты HR-процессов на каждом этапе.
В последние годы SimbirSoft активно растет и вместе с тем занимается вопросами сохранения специалистов. Мы постоянно исследуем новые подходы и возможности для создания взаимовыгодных отношений с сотрудниками на длительный срок. Часто бизнесу не очевидно, какие факторы влияют на решение покинуть компанию и какие превентивные действия можно предпринять, чтобы уменьшить отток.
Чтобы выявить скрытые взаимосвязи и определить ключевые факторы, которые мотивируют сотрудников продолжать сотрудничество с компанией, мы решили провести внутреннее исследование и использовать ML-технологии для анализа и обработки накопленных данных.
Основная задача исследования — оценить, насколько точно модель может прогнозировать вероятность ухода специалиста в течение одного месяца после обращения к HR-менеджеру и какие факторы на это влияют. Забегая вперед, скажем, что мы создали инструмент, который позволяет более эффективно выявлять сотрудников, находящихся в зоне риска, и реагировать на это заранее.
Спойлер: Обученная ML-модель не только обнаруживает сложные нелинейные взаимосвязи между признаками, но и количественно оценивает их важность для принятия сотрудником решения об увольнении.
Какое решение задачи выбрали
В процессе выбора решения для прогнозирования увольнений сотрудников мы остановились на использовании моделей классического ML. Это было связано с необходимостью получения решения с высокой объяснимостью. Нейросетевые методы ИИ меньше подходят для такой задачи по причине их нативной природы «черного ящика» (black box).
Мы рассмотрели несколько подходов:
- линейную модель логистической регрессии
- нелинейные модели
- ансамблевые методы на основе деревьев решений — случайный лес (Random Forest) и градиентный бустинг (Extreme Gradient Boosting, XGBoost).
Наиболее удачным оказался XGBoost: обученная архитектура давала наибольшую точность прогноза при достаточной интерпретируемости результатов.
Основной принцип работы модели — способность анализировать множество факторов, влияющих на решение об увольнении. Мы стремились выявить закономерности в данных, которые могут сигнализировать о высокой вероятности скорого увольнения специалиста. Для этого мы обучали модель на исторических данных, проверяя стабильность ее работы на отложенной выборке — фрагменте исходных данных, которые модель не видела при обучении.
Какие алгоритмы и методы работы использовали
Для проведения исследования мы использовали:
- Градиентный бустинг
Мы выбрали алгоритм градиентного бустинга из-за его высокой эффективности в задачах классификации. Этот метод строит ансамбль слабых моделей, последовательно улучшая их и минимизируя ошибки на каждом этапе. Градиентный бустинг хорошо справляется с нелинейными зависимостями и взаимодействием между признаками. Это критично для анализа неоднородных данных, таких как поведение людей, на которое влияет множество факторов, в том числе скрытых. - Предобработка данных
Перед обучением модели мы провели этап предобработки данных, который включал их очистку, обработку пропусков и кодирование категориальных переменных. Подобные признаки могут принимать ограниченный перечень значений категорий, например, пол — мужской или женский, подразделение — Backend, Frontend, QA и другие. Поскольку алгоритмы могут принимать на вход только числовые значения, категориальные переменные мы трансформировали в векторы из нулей и единиц с помощью One-Hot Encoding. Кросс-валидация
Для оценки производительности мы использовали кросс-валидацию, которая предоставляет более надежные оценки качества модели. Метод позволяет разбить данные на несколько подмножеств и обучить модель на разных частях данных. Это помогает избежать переобучения — эффекта, когда модель заучивает текущие данные и хуже обобщает закономерности на новых данных.
- Интерпретация и визуализация результатов
После обучения модели мы использовали методы интерпретации, такие как векторы Шепли (Shapley values), чтобы понять влияние различных признаков на качество предсказания модели. Это поможет определить, какие факторы наиболее существенно влияют на вероятность увольнения сотрудников.
На какие данные опирались
Для разработки модели прогнозирования увольнений сотрудников мы опирались на несколько категорий данных, которые собрали из различных источников внутри компании. Они включали количественные и качественные характеристики специалистов.
Данные были собраны на основе истории обращений сотрудников к HR, когда мы имели точную информацию, что у человека возникли проблемы, а значит, нужно оценить риск увольнения сотрудника через месяц после последнего обращения. Поскольку 1 месяц — примерный срок закрытия вакансии в компании.

Основные типы данных, которые мы использовали:
1. Демографические данные: возраст, пол, семейное положение, количество детей
2. Данные о работе
- Отдел
- Стаж в компании
- Количество смен непосредственного руководителя внутри компании
- Опыт руководителя
- Категория обращения сотрудников: размер заработной платы, тип команды, личные причины и прочее
- Средняя продолжительность предыдущих обращений: период с момента регистрации в системе до момента закрытия случая
- Процент положительных решений обращений до настоящего момента
- HR-специалист, который обрабатывает обращение
- Наличие офиса в городе пребывания, то есть возможности физического присутствия на рабочем месте в офисе
Исследовательские данные охватывали период с июля 2022 года по апрель 2024 года. Вся информация была анонимной, конфиденциальные сведения не включались в исследование.
Эти сведения стали основой для построения модели прогнозирования, которая позволила выявить паттерны и факторы, способствующие увольнению сотрудников.
Как решали задачу
Целью нашего исследования было создание ML-инструмента для наиболее точного прогнозирования риска увольнения сотрудника в течение месяца после обращения к HR-специалисту с какой-либо проблемой.
Исследование включало 5 основных этапов: формулировка исследовательских вопросов и гипотез, формирование набора исторических данных, базовая предобработка данных, анализ данных, интерпретация результатов.
1 этап — Формулировка исследовательских вопросов и гипотез
Принятие решения о смене работы может иметь бытовые, семейные, личные и другие причины. Увольнение практически всегда сопряжено с текущим эмоциональным состоянием сотрудника, поэтому невозможно в каждом случае определить, что именно вынудит человека уйти. Однако мы выдвинули ряд предположений, основываясь на наших наблюдениях за сотрудниками компании на протяжении многих лет работы.
Гипотеза 1. Демографические факторы оказывают значительное влияние на решение сотрудника об увольнении. Например, молодые сотрудники более склонны к смене работы, чем более опытные. Кроме того, в IT сфере до сих пор наблюдается гендерная диспропорция среди сотрудников — мужчин работает в разы больше, чем женщин. Вероятно, гендерные различия можно отследить и в паттернах увольнения. Сотрудники с большим количеством детей более склонны оставаться на работе из-за необходимости обеспечивать семью.
Гипотеза 2. На решение об увольнении влияют факторы социального окружения сотрудника. Например, наличие физического офиса влияет на уровень взаимодействия между сотрудниками и удовлетворенность работой. Отдел, в котором работает специалист, может быть более или менее стабильным, что влияет на вероятность увольнения. Кроме того, стаж в компании и опыт непосредственного руководителя также отражаются на стабильности команды и вероятности увольнения специалистов.

Гипотеза 3. Сотрудники с бόльшим стажем работы на текущем месте более склонны оставаться на работе из-за лояльности к компании, в то время как новые сотрудники еще не имеют сформированной привязанности.
Гипотеза 4. Частая смена непосредственного руководителя, как правило, вызывает нестабильность и неуверенность среди специалистов, что может привести к увеличению вероятности увольнения.
Гипотеза 5. Руководители с большим опытом работы могут иметь более стабильную команду и меньше увольнений, в то время как менее опытные руководители могут столкнуться с проблемами адаптации и увольнениями.
Гипотеза 6. Обращения, связанные с размером заработной платы, могут указывать на неудовлетворенность сотрудника и повышенный риск увольнения. Вопросы заработной платы часто оказываются одними из самых актуальных и значимых, поскольку материальная мотивация в большинстве случаев играет ключевую роль в сохранении сотрудников.
Гипотеза 7. Длительные периоды решения проблем сотрудника могут указывать на низкое качество работы HR-специалиста и увеличивать вероятность увольнения.
Этап 2 — Формирование набора исторических данных
Мы собирали данные из нескольких источников:
- Демографические данные о сотруднике: возраст, пол, семейное положение и количество детей — информация из 1С.
- Данные об истории взаимодействия с компанией: стаж, команда, возможность посещать офис, опыт руководителя, категория проблемы, с которой сотрудник обратился к HR — информация из внутренней HRM-системы.
- Переменные, которые мы дополнительно создали для исследования: количество смен руководителя, среднее количество успешно решенных обращений в прошлом, средняя продолжительность предыдущих обращений. Исходную информацию для создания переменных мы взяли из внутренней HRM-системы.
Этап 3 — Предобработка данных
Базовая предобработка данных перед использованием в ML-модели состоит из:
- Очистки данных: удаления дубликатов, обработки пропусков и аномалий
- Кодирования категориальных переменных: преобразования текстовых данных в числовые форматы (например, «категория обращения»)
- Нормализации: приведения данных к единому масштабу, если это необходимо
Этап 4 — Анализ данных
На этом этапе мы провели:
- Разведочный анализ данных (EDA, exploratory data analysis). Использование описательной статистики по переменным, корреляционный анализ и визуализация переменных и отношений между ними.
- Выбор подходящих алгоритмов и гиперпараметров моделей. Мы работали с тремя основными алгоритмами классического ML — логической регрессией, случайным лесом и градиентным бустингом.
- Обучение модели. Для получения надежной оценки результата мы обучали модель методом кросс-валидации, когда данные многократно случайно делятся на обучающий и тестовый наборы. На обучающем наборе модель учится обобщать закономерности, а на тестовом проверяется качество обучения. Затем результаты работы модели на всех тестовых выборках усредняются.
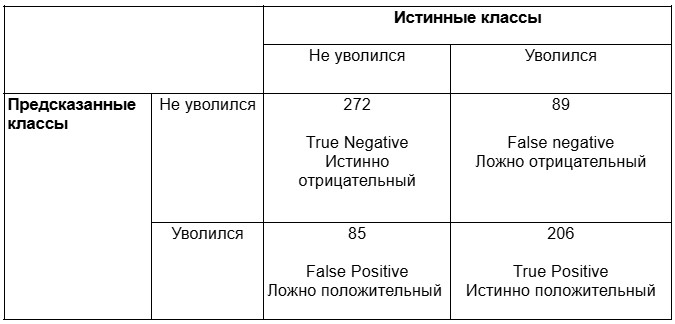
- Выбор оптимальной модели и принципов ее построения в ходе обучения. На основании метрик кросс-валидации мы выбрали лучшее сочетание модели и гиперпараметров, которые определяют ее архитектуру. Наилучшие показатели продемонстрировала модель градиентного бустинга XGBoost:
Этап 5 — Интерпретация результатов
На этом этапе мы проанализировали факторы, которые оказывают наибольшее влияние на вероятность увольнения, что помогло нам в разработке будущих стратегий удержания сотрудников.
Процесс интерпретации результатов охватывает основные шаги для решения задачи прогнозирования увольнений сотрудников. При этом он может варьироваться в зависимости от специфики компании.
Какие результаты получили
Обученная модель градиентного бустинга XGBoost лучше остальных справилась с задачей предсказания увольнений.
В нашу модель входило 22 признака, однако не все они имели большое значение. Исследование показало, что риск скорого увольнения связан в большей степени с опытом работы в компании (стаж), командой (опыт руководителя) и опытом взаимодействия с HR (средняя продолжительность и количество предыдущих обращений). Из всех демографических факторов только возраст сотрудника вошел в топ-10 признаков по важности.
Наша работа представляет собой первичное исследование, основанное на доступных данных. Внедрение модели в HR-процессы компании может занять некоторое время, которое мы планируем использовать для дообучения модели, тестирования на новых данных и добавления признаков, связанных с профессиональным ростом внутри компании.
Ключевые выводы
Область HRTech стремительно развивается благодаря внедрению искусственного интеллекта, что позволяет существенно оптимизировать процессы подбора, адаптации и обучения сотрудников. В 2024 году одной из ключевых задач для бизнеса стало сохранение талантливых специалистов в условиях дефицита опытных кадров, особенно на IT-рынке.
Прогнозирование увольнений сотрудников — многогранная задача, которая требует комплексного подхода и внимания к деталям. Компании должны внимательно анализировать факторы, способствующие уходу сотрудников, чтобы своевременно реагировать и минимизировать риски. Успешные примеры показывают, что прогнозирование увольнений может привести к значительной экономии, позволяя сохранить до 70% ключевых сотрудников.
Использование современных технологий и методов анализа данных может значительно улучшить понимание причин текучести кадров и помочь в разработке эффективных стратегий удержания сотрудников.
Мы создали инструмент, который позволяет более эффективно выявлять сотрудников, находящихся в зоне риска увольнения, и реагировать на это заранее
Источники изображений:
Freepik.com
Рубрики
Интересное:




Новости отрасли:


Все новости:




Публикация компании
Рубрики