
Поиск среди десятков тысяч файлов: ИИ-помощник в проектной документации
Как ИИ помог сократить время поиска электронной документации в десятки раз и сэкономить 400 часов на команду в месяц для крупной строительной компании
Задача
Снять с сотрудников рутинный процесс ручного поиска чертежей, схем, отчетов, текстов — и многократно повысить скорость и точность обработки.
Причина
У крупных компаний в области строительства общее число документов по каждому проекту достигает нескольких сотен тысяч. Ручной, медленный и неэффективный поиск серьезно замедляет операционные процессы и дополнительно увеличивает финансовые затраты. Ошибки из-за человеческого фактора несут прямые риски вплоть до юридических издержек и компрометации безопасности конструкций.
Недвижимость — это сотни процессов: техническая эксплуатация, безопасность, аренда, документооборот, отчетность. Каждый из них генерирует данные в огромных количествах. Работа с чертежами — один из самых уязвимых этапов. На согласование может уйти несколько месяцев, а возврат на доработку из-за мелкой ошибки (например, комната без двери или неверное положение деталей) займет много времени и трудозатрат — при том, что многие из них идут на согласование параллельно.
Отчеты для инвесторов включают сверки и анализ документов за огромный период работы, и на агрегацию могут уходить целые дни. Руководители, обладая полной и достоверной картиной, получают возможность принимать более точные решения и упреждать риски.
С юридической точки зрения быстрый доступ к файлам помогает своевременно и аргументированно ответить на претензию, выиграть судебный спор и избежать необоснованных выплат.
Заказчик
Крупный девелопер и генеральный подрядчик с полным циклом работ: от проектирования до строительства. В штате находятся несколько тысяч сотрудников, проектный и инженерный блок насчитывает около 300 человек. Объем документов, с которыми им приходится работать, — от 100 до 150 тысяч файлов, в том числе весом более 1 ТБ.
До внедрения автоматизированного ИИ-поиска у компании был типичный для отрасли вызов:
- инженеры разных направлений — архитекторы, конструктора, специалисты по электрике, водоснабжению, сметам и согласованиям — тратили часы на поиск нужного файла;
- в среднем один человек искал документы от 2 до 5 часов в неделю, при этом часть времени уходила на работу с устаревшими версиями или дубликатами;
- в сумме это приводило к сотням часов потерь в месяц только на одном проекте;
- ошибки и несоответствия обнаруживались поздно — на этапе согласования или даже строительства, что грозило масштабными исправлениями и задержками.
Решение
Мы создали единый портал с OCR-модулем, централизованной базой метаданных и семантическим поиском. Интеллектуальный поисковик проектной документации способен распознавать и анализировать документы с помощью компьютерного зрения, искать документы по ключевым словам, структуре проекта и даже по смыслу, сверять файлы для поиска несоответствий и дубликатов. Подходит как в виде облачного сервиса, так и для локальной установки во внутренний контур компании с интеграцией в ИТ-инфраструктуру.
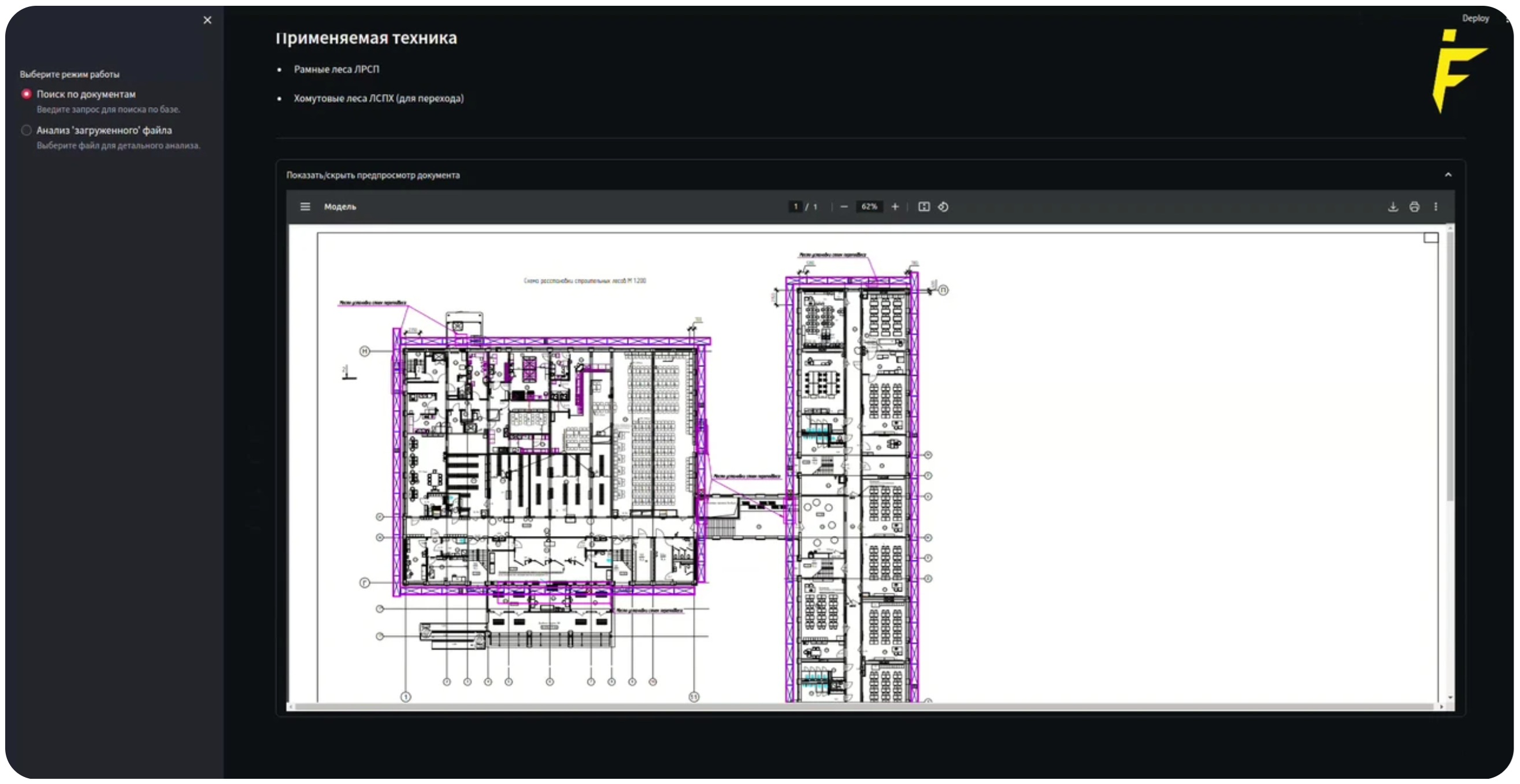
Детали разработки
1. Видение продукта и подготовка CJM
В течение 1,5 месяца мы агрегировали и изучали все данные проектной документации за 5 лет, затем взяли их в основу будущей интеллектуальной базы данных. Параллельно проводили интервью с сотрудниками, которые работают с этими документами, для составления оптимального клиентского пути.
Выяснили инсайты: например, чаще всего инженеры детально знают только свои проекты и не посвящены в направления других коллег, хотя их документация может быть взаимно полезна для обеих сторон. А без объединенной базы данных людям приходится держать в уме все ключевые слова, чтобы определить, в каких папках искать документы, в то время как реальное и предполагаемое расположение может не совпадать.
На основе этого этапа мы определили CJM и архитектуру будущего решения. Работали локально внутри сети клиента.
2. Разработка MVP
В течение 2 месяцев команда спроектировала первую версию MVP, начав с интеллектуального поиска на основе базы знаний. При поиске используются метаданные файлов (название, автор, дата изменения) и векторный поиск по смыслу, а также LLM-фильтрация и составление рекомендаций.
Поисковая система изначально тестировалась на синтетических данных. Это не настоящие документы заказчика, а их точная и безопасная копия по структуре и содержанию. Были созданы датасеты, которые повторяли запросы пользователей.
3. Дальнейшее тестирование и настройка
За следующие 2 месяца велась пилотная работа, пользователи ежедневно давали оценку выданным результатам по поиску и рекомендациям по приоритету. Обратная связь транслировалась команде разработки для улучшения системы в режиме итераций.
4. Финализация
В последний месяц заказчик испробовал систему в опытной эксплуатации, в том числе замеряя бизнес-эффекты. По итогам система была полностью передана в пользование компании и условиями технической поддержки.
С чем мы столкнулись в процессе
- Проектная документация крайне разнородна. В одном проекте может находиться 10 основных файлов, которые структурно правильно разделены на части, а в другом может быть больше или меньше аналогичных, часть которых включает сразу несколько тематик. Поисковая документов должна грамотно функционировать как в первом, так и во втором случае.
- Файлы объемные, «тяжелые». Каждый раз заново считывать их целиком при каждом запросе — медленно и малоэффективно. Поэтому мы выстроили процесс так, что при загрузке каждого документа в систему он проходит полную предварительную обработку. На основе его содержимого создается набор специальных меток с ключевой информацией.
- Процент неверного предоставления ответов LLM на первых этапах составлял 5%, что нежелательно для автоматизированного инструмента. С последующей доработкой этот показатель упал до 0,1%.
Для сравнения, в среднем ИИ-поисковики документов узконаправленной специализации — например, в медицине — могут ошибаться в 1,47–3,45 процентах случаев. У других ИИ-помощников в более «широких» масштабах — юридической базе или всей корпоративной переписке — диапазон ошибочных ответов может составлять от 17 до 33 процентов.
- Документация часто включает схемы и тексты, написанные от руки, которые проблематично включать в базу данных. По мере совершенствования алгоритма, OCR достиг точности 99,7%. Дополнительный анализ с помощью LLM помог с большей точностью анализировать даже некачественные отсканированные файлы, определять контекст, распознавать содержание и выделять ключевые детали.
После запуска интеллектуального поисковика проектной документации от Студии Искусственного Интеллекта FOKINA.AI фактические результаты превысили ожидания.
- KPI: уменьшить время нахождения нужных чертежей и текстов минимум в 5 раз. Результат: мы сократили поиск намного сильнее — с 2–5 часов в неделю до 2–5 минут.
- KPI: повысить эффективность работы команд минимум на 20%. Результат: производительность выросла на 30%.
- KPI: освободить не менее 200 часов ежемесячно на всех пользователей инструмента. Результат: экономия до 400 часов в месяц.
Рубрики
Интересное:




Новости отрасли:


Все новости:




Публикация компании
Профиль
Социальные сети
Рубрики