
Восстановление ИТ-инфраструктуры: цена простоя для бизнеса
Полный отказ ИТ-инфраструктуры — это не «если», а «когда». Разбираемся, почему бэкапа недостаточно и как бизнесу не терять миллионы из-за простоя

ИТ-эксперт с 25-летним стажем. «Лечит» ИТ-инфраструктуру бизнеса: ставит диагноз процессам и выстраивает систему, которая стабильно работает на результат
Полный отказ ИТ-инфраструктуры способен мгновенно парализовать бизнес. Привычные для крупного ритейла или онлайн-сервиса риски простоя стали ежедневной реальностью для всей экономики — от среднего бизнеса до госкомпаний. Одно технологическое падение может привести к потерям в миллионы и поставить под удар репутацию бренда. Почему нельзя надеяться «на авось», что работает в России и как внедрить эффективный Disaster Recovery Plan (DRP) — в этой статье.
ИТ сбой — это не «если», а «когда». Компания может быть устойчива к десяткам внешних атак, но одна неверная логика в скрипте, сбой в оборудовании или неудачное обновление — и вся система лежит. Выдерживать такие потрясения способны только те бизнесы, кто инвестировал в жизнеспособную инфраструктуру: распределенные серверы, облачные реплики и ясные роли в плане аварийного восстановления (DRP).
Бизнес под ударом: причины сбоев
К концу 2025 года ИТ-риски для российского бизнеса не исчезли, а трансформировались:
- Гибридные кибератаки. На смену обычным DDoS-атакам пришли многовекторные угрозы, сочетающие взлом инфраструктуры поставщиков и целевой фишинг с использованием AI.
- Цена утечки данных. После ужесточения 152-ФЗ о персональных данных в 2025 компрометация персональных данных — это не просто репутационный ущерб, а риск многомиллионных штрафов, остановки бизнеса
- «Технологический зоопарк». Последствия спешного импортозамещения: десятки несовместимых друг с другом отечественных решений, которые сложно и дорого поддерживать.
- Хрупкость инфраструктуры. Сбои оборудования из-за перегрузок, отключений энергии или физических инцидентов по-прежнему парализуют бизнес.
Реальный кейс: Банальная ошибка проектирования серверной — и бизнес теряет налоговую отчетность, CRM и доступ к единой базе заказов. Владелец компании рассказывает: «Мы думали, что бэкап — это и есть план восстановления».
Что значит План аварийного восстановления (Disaster Recovery Plan)
Многие руководители все еще путают план аварийного восстановления (Disaster Recovery Plan, DRP) с резервным копированием. Однако бэкап — это лишь сохраненные данные, в то время как DRP — это комплексный бизнес-процесс, который позволяет эти данные (и всю компанию) вернуть к жизни после сбоя.
Disaster Recovery Plan — это не папка с инструкциями на случай «апокалипсиса», а живая экосистема, которая объединяет IT и бизнес-подразделения для одной цели: минимизировать простои и финансовые потери. Если бэкап — это спасательный круг, то DRP — это вся работа спасательной службы: от команды на борту до логистики на берегу.
Что на самом деле включает в себя DRP
Эффективный план аварийного восстановления — это всегда больше, чем просто технологии. Он строится на трех ключевых элементах:
- Регламенты и зоны ответственности. Четкий сценарий, где прописано, кто и в какой последовательности действует. Кто принимает решение о запуске DRP? Какая команда отвечает за восстановление серверов, а кто — за коммуникацию с клиентами и партнерами? Без этого в момент кризиса начнется хаос.
- Технологическая платформа. Это не только создание резервных копий, но и их размещение на географически удаленной площадке, технологии репликации данных и, что критически важно, регулярное тестирование восстановления. Ключевые метрики здесь — RPO (допустимый объем потери данных, например, за 1 час) и RTO (целевое время восстановления, например, 4 часа).
- Стратегия коммуникаций. Заранее подготовленные сценарии и шаблоны для оповещения ключевых аудиторий: клиентов, партнеров, сотрудников и, в некоторых случаях, регуляторов. Молчание в кризисной ситуации наносит репутационный ущерб, сравнимый с финансовыми потерями от простоя.
Бизнес часто подходит к вопросу так: «У нас есть бэкапы, мы в безопасности». Но когда происходит реальный сбой, выясняется, что никто не знает, как и в какой последовательности их разворачивать. В итоге восстановление затягивается на дни, а потери растут в геометрической прогрессии.
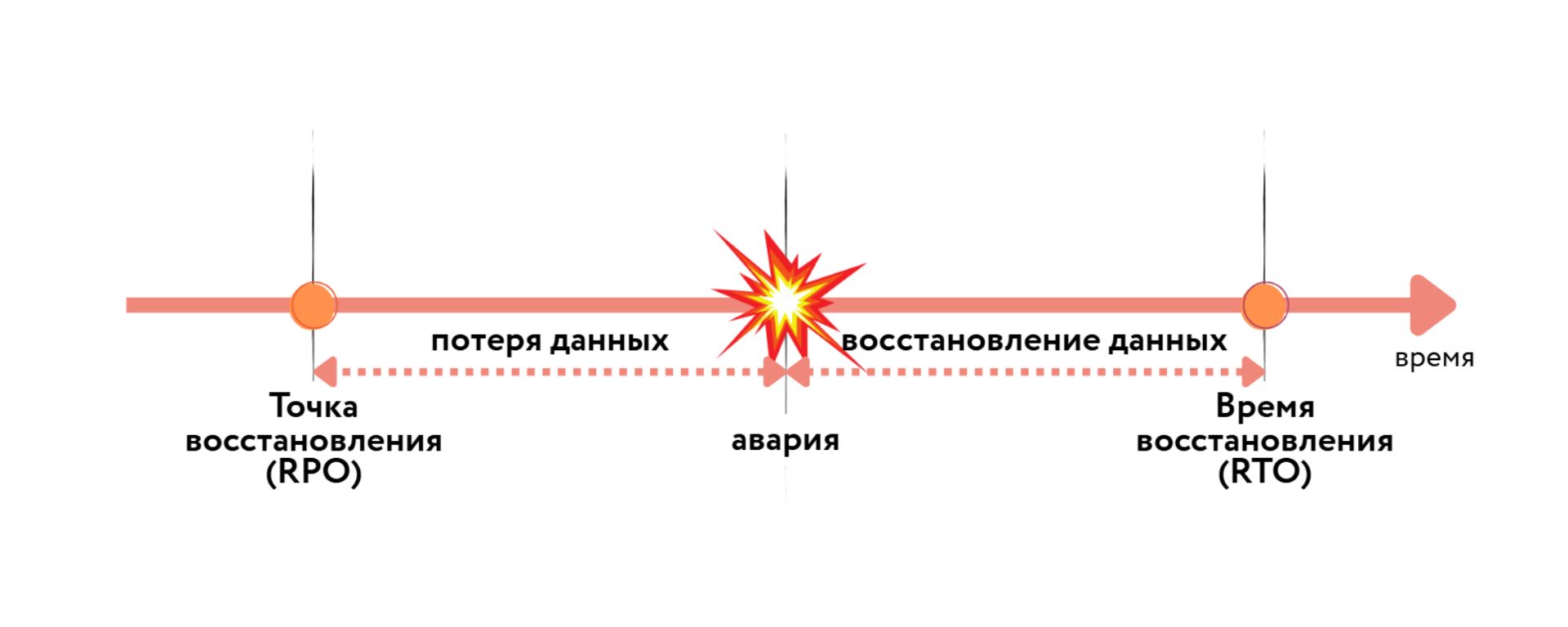
RPO и RTO: язык переговоров между ИТ и бизнесом
Непрерывность — это не преимущество, а базовое условие выживания. В этом контексте ключевыми метриками становятся RPO и RTO. Это не просто технические термины, а основа для диалога между IT-директором (CIO) и генеральным директором (CEO), позволяющая оценить устойчивость бизнеса в финансовых показателях.
RPO (Recovery Point Objective) — точка восстановления. Это ответ на вопрос: «Данными за какой максимальный период мы готовы безвозвратно пожертвовать?». Если RPO составляет 1 час, это значит, что в случае сбоя компания потеряет всю информацию, созданную за последний час.
RTO (Recovery Time Objective) — целевое время восстановления. Отвечает на вопрос: «Как быстро ключевые бизнес-сервисы должны быть снова в строю?». Это время, за которое IT-служба обязана восстановить работоспособность систем после объявления аварии.
Цена каждой минуты: от теории к практике
Эти метрики напрямую влияют на финансовые результаты. Для онлайн-магазина с небольшим трафиком RPO в 15 минут означает потерю заказов, что некритично. Но для системы банковского процессинга такой же показатель может привести к хаосу в транзакциях и потере доверия клиентов.
Аналогично с RTO: если для корпоративного портала или системы внутреннего документооборота простой в 4 часа — это неприятно, но не критично для ключевых операций, то для логистического оператора аналогичный сбой в работе склада может вызвать коллапс цепочек поставок на несколько дней вперед.
Диалог об RPO и RTO — это перевод технических требований на язык финансовой модели. IT-директор должен прийти к CEO не с просьбой о бюджете на серверы, а с расчетом: час простоя CRM-системы стоит нам X миллионов рублей из-за потерянных сделок. Сокращение RTO с четырех часов до одного будет стоить Y, но снизит потенциальные потери в четыре раза. Это чистое инвестиционное решение.
Российская практика: искусство компромисса
Стремление к «нулевым» показателям RPO и RTO — то есть к полному отсутствию потерь данных и мгновенному восстановлению — достижимо, но требует колоссальных инвестиций в дублирующую инфраструктуру (так называемый «горячий» резерв). На практике российский бизнес ищет компромисс. Оптимальные значения RPO и RTO определяются не в теории, а по итогам стресс-тестов: моделирования кибератаки или другого сбоя, которые наглядно демонстрируют, сколько на самом деле будет стоить компании каждый час простоя. Именно после этого финансовый и IT-блок могут прийти к взвешенному решению о необходимом уровне защиты.
Основные сценарии восстановления и повышения отказоустойчивости инфраструктуры
На отечественном рынке активно применяют стратегии:
- Резервное копирование (Backup)
Носители: NAS, оптические, облака.
Минус: часто забывают уводить копии за пределы здания — реальные кейсы в Москве и Санкт-Петербурге. - Облачный DRaaS
Развертывание резервной копии в российском облаке, поддержка документооборота по SLA. - Репликация рабочих нагрузок и виртуальных машин
Время отклика — минуты, потери данных минимальны. - Горячий резерв (Hot Site)
Самое дорогое, но обеспечивает отказоустойчивость на уровне международных стандартов и сертификации Tier-III.
Сравнительная таблица для топ-менеджмента:
Выбор стратегии восстановления — это всегда компромисс между скоростью, полнотой сохранения данных и бюджетом. Чтобы помочь руководителям принять взвешенное решение, мы свели ключевые параметры популярных сценариев в одну таблицу. Она наглядно показывает, какой ценой достигается та или иная степень защиты бизнеса от ИТ-катастроф.

Этапы построения DRP: дорожная карта для CEO и CIO
Чтобы план аварийного восстановления не остался на бумаге, а стал реальной гарантией стабильности бизнеса, его внедрение должно проходить по четко выстроенному алгоритму. Вот ключевые шаги, которые предстоит пройти:
- Аудит — независимая оценка рисков ИТ-инфраструктуры.
- Выбор целевых метрик RTO и RPO для разных сервисов и бизнес-процессов.
- Формирование бюджета и подбор технологии (пути: backup, репликация, DRaaS, hybrid).
- Документирование. Создание DRP планов.
- Учения: тестирование команды по восстановлению «на живую» и в изоляции (sandbox), минимум 1–2 раза в год.
- Актуализация: план пересматривается после каждого существенного изменения в инфраструктуре либо законодательства.
Как выбрать ИТ-партнера
Выбор ИТ-партнера — не сухая сделка, а та самая точка невозврата, ведь ошибка рискует обернуться потерей контроля над инфраструктурой. Надежного исполнителя отличают совсем не самые низкие цены или громкие лозунги, а редкая смесь спокойствия и доказанных решений, которые работают «на земле».
По-настоящему зрелый интегратор:
- Имеет портфолио и живые кейсы, которыми с гордостью делится в открытых источниках.
- Не обещает золотых гор, а находит компромисс между «безумным» бюджетом и минимально допустимым риском для бизнеса.
- Спокойно выводит на реальных специалистов своей команды — говорит: «Завтра созвон с нашим архитектором, он знает вашу отрасль глубоко».
- Готов предложить пилотный запуск (DRP-учения) — чтобы вы могли почувствовать весь сценарий и работу команды интегратора на пике стресса, без риска для рабочих данных.
- Открыто декларирует условия поддержки по SLA: вам доступны квалифицированные инженеры 24/7, и это не просто слоган на сайте.
Не стесняйтесь просить прямые контакты клиентов из вашего сектора — лучшие подрядчики не скрывают свою работу. Посетите офис интегратора, поговорите с командой.
Настоящее партнерство — это когда ваш подрядчик вовлечен в бизнес и болеет за ваше дело не меньше, чем вы сами. Ведь в момент, когда сервер скажет «прощай», на сцену выйдет не красивый сайт, а люди, готовые спасать ваш бизнес в любую погоду.
Источники изображений:
Архив ALP ITSM
Рубрики
Интересное:




Новости отрасли:


Все новости:




Публикация компании
Контакты
Социальные сети
Рубрики