
Как с небольшими затратами создать систему сбора данных о состоянии рынка
Рассказываем, как на одном из коммерческих проектов помогали создать автоматизированную систему сбора данных из открытых источников и анализа рынка зерна
Клиент создавал площадку для торговли зерном и сам являлся одним из покупателей-посредников. Задача — создать приложение для сбора данных торгов на покупку, продажу и перевозку сельскохозяйственной продукции для последующего анализа рынка зерна.
Данная информация должна помочь в принятии решений, минимизировать риск и повысить прибыль компании.
В современном высококонкурентном и изменчивом мире для успешного развития бизнеса необходим постоянный мониторинг и анализ статистических данных о состоянии отрасли. Ранее мы уже рассказывали, как ИТ меняют АПК.
В этой статье — о том, как на одном из коммерческих проектов помогали создать автоматизированную систему сбора данных из открытых источников и анализа рынка зерна. Какие преимущества это дает и как с минимальными затратами начать сбор открытых данных из Сети — далее.
Преимущества сбора и анализа статистических данных о рынке отрасли
Система сбора и анализа данных о состоянии рынка позволяет:
- Оценивать эффективность деятельности бизнеса. Анализ продаж, маркетинга, производства и финансов дает возможность определить слабые и сильные стороны компании, а также выявить возможности для повышения конкурентоспособности.
- Принимать обоснованные решения. Анализ данных, выявление закономерностей и тенденций позволяет бизнесу принимать верные решения, основываясь на эмпирических данных, а не на интуиции или предположениях.
- Оценивать риски и их влияние на деятельность компании. Понимание вероятности и потенциального воздействия различных рисков позволяет принимать превентивные меры для их снижения, повышая устойчивость и адаптивность бизнеса к изменениям на рынке.
- Разрабатывать эффективные маркетинговые стратегии, запускать новые продукты и поддерживать конкурентоспособность. Анализ тенденций, поведения потребителей и конкурентов позволяет компаниям определить свои уникальные преимущества и разработать стратегию, которая будет способствовать успешному развитию бизнеса.
- Оптимизировать ресурсы. Данные помогают составить бюджет, распределить рабочую силу и управлять запасами, обеспечивая эффективное использование всех доступных ресурсов.
Сбор и анализ статистических данных о состоянии рынка отрасли — ключевой фактор успешного развития бизнеса. Такая информация дает возможность повышать эффективность деятельности, минимизировать риски и достигать успеха, обеспечивая устойчивое развитие и конкурентоспособность на рынке.
Шаг 1 — Определяемся с целевой аудиторией приложения
Среди игроков рынке зерна можно выделить три основных аудитории. Причем приложение может быть направлено как на кого-то конкретного, так и объединять все три группы.
1. Продавцы. Производители сельскохозяйственной продукции, фермеры.
Для продавцов важно понимать, по какой цене сейчас компании закупают зерно и кто платит за перевозку: фермер сам должен организовать доставку покупателю или покупатель направит свои машины по условиям CPT (Carriage Paid To), FCA (Free Carrier). Если перевозка — на фермере, он будет зависеть от точки выгрузки (базиса), а значит чем она дальше, тем меньшую маржу от продажи зерна он получит.

2. Покупатели. Трейдеры, которые закупают зерно для экспорта, крупные агрохолдинги, фасовщики и производители продукции.
Для покупателей важно следить за конкурентами и привлекать фермеров более выгодными условиями, а также следить за качеством приобретенного зерна и искать контракты.
3. Перевозчики.
Для перевозчика важно понимать, где и когда пойдут основные потоки продукции. Откуда и куда везут, по какой цене. Важно найти наиболее выгодные контракты по перевозке. Следить, чтобы автопарк, вагоны и корабли (баржи) не простаивали.
Среди прочих участников рынка можно выделить хранилища (элеваторы), лаборатории по оценке качества продукции, различных посредников (тендерные площадки, доски объявлений и электронные биржи). Есть перспективные планы по их интеграции в систему, но в текущей версии мы их не использовали.
В последнее время тренды на рынке зерна задают крупные покупатели. Участники рынка ориентируются на их официальные закупочные цены и на выставляемые ими характеристики качества закупаемой продукции. Также на ценообразование влияют ставки вывозных таможенных пошлин, которые публикует Минсельхоз, и другие факторы: период года, погода, количество собранного урожая и прочее.
Анализируя эти данные, участники рынка пытаются принять важные для себя решения:
- когда и сколько продавать/покупать, чтобы получить наибольшую выгоду от контракта (для продавцов и покупателей),
- где и когда обеспечить наличие необходимого для выполнения перевозки транспорта (для перевозчиков).
Сейчас можно получать много полезных данных из открытых источников в Сети, проводить их ручной и автоматизированный анализ, предсказывать тренды и на их основе принимать важные решения.
Далее расскажем, как можно организовать сбор этих данных с помощью автоматизированной системы.
Шаг 2 — Создаем приложение
Организация сбора данных
Сначала важно было определиться, какие данные нас интересуют. Клиент создал площадку для торговли зерном и сам являлся одним из покупателей-посредников. Задача — разработать приложение для сбора данных торгов на покупку, продажу и перевозку сельскохозяйственной продукции, ее номенклатуры, параметров качества, цены.
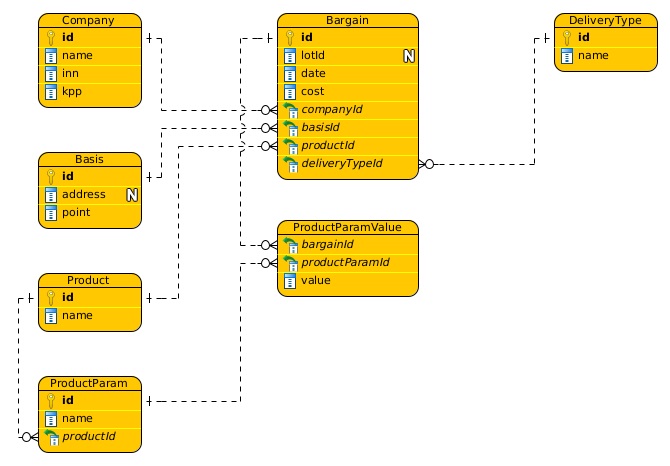
Исходя из этого строилась модель данных, ключевыми сущностями которой были:
1. Организация (Company) — юридическое лицо, которое объявляло о намерениях что-то продать, купить или перевезти в публичных источниках. Ключевыми данными для ее идентификации были ИНН и КПП.
2. Базисы (Basis) — точки погрузки/выгрузки продукции. Ключевые данные — координаты этих точек на карте.
3. Торги (Bargain), продукция (Product), ее качественные характеристики (ProductParam, ProductParamValue), цена (cost), тип перевозки (DeliveryType), дата (date) и прочее.
В итоге получилась примерно следующая модель данных:
Далее нужно было выбрать наиболее важные источники в сети Интернет для получения интересующей нас информации. Чтобы выявить крупных участников и популярные сервисы, заказчик провел исследование. Для обращения к некоторым источникам требовалась интеграция по API, и этот фактор влиял на выбор архитектуры.
Также требовалось соблюдать законодательство и правила используемых сервисов, и при необходимости получать у них письменное разрешение на автоматизированный сбор данных для личных целей.
Некоторые источники, например, прайсы, обновляются не часто. Система могла считывать даты выкладки прайса и обращаться к ним раз в сутки. Если дата обновилась, обрабатывать новую информацию. С досок объявлений и бирж данные можно получать чаще, поскольку торги проходят за считанные часы. Кроме того, и сами данные по торгам могут обновиться, например, измениться объем, цена или базис.
Создание архитектуры
При разработке архитектуры ПО используют две основные концепции — монолиты и микросервисы. Для получения данных из каждого источника можно использовать отдельный микросервис, а затем агрегировать данные в одну общую базу данных. Такая архитектура более эффективна при обработке сотен источников в режиме онлайн.
В рамках проекта потребовался анализ относительно небольшого количества источников: сайты ключевых игроков и несколько самых популярных сервисов в отрасли. Данные с большей части из них можно собирать не чаще раза в сутки.
При таких исходных данных оптимальной архитектурой выбран модульный монолит. В результате получился один Node.js-проект средней сложности, с которым может справиться один Node.js-программист уровня middle. Основные модули приложения были написаны в течение двух недель, а далее добавлялись дополнительные модули.
Как работали с подводными камнями
При увеличении числа источников затраты на поддержку также росли. Это было связано с периодической мутацией источников. В частности, сайт или сервис могли поменять свою страницу или API, или пользователи сервисов могли делать что-то неожиданное, например, неправильно написать название культуры на доске объявлений.
У собранных данных нужно было уточнять организацию (встречались разные написания названия одной и той же организации), базис (по адресу попытаться получить координаты). Для автоматизации этой работы мы подключили внешние сервисы типа dadata. Но иногда требовался ручной анализ и уточнение данных.
Если система не смогла идентифицировать сущность, она переводила ее в статус «ожидания уточнения информации». В ежедневном отчете, который приходил на электронную почту, команда получала информацию о том, что есть такие сущности и по ним нужно уточнить данные.
В среднем обработка информации занимала от 2 до 6 часов в день.
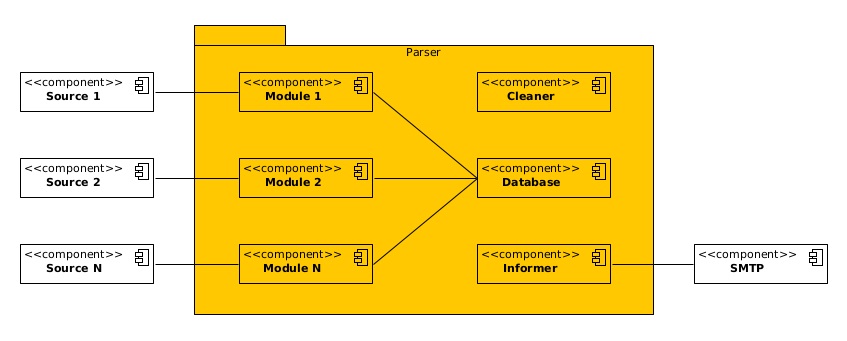
На рисунке изображена примерная архитектура получившегося приложения. На каждый источник был написан свой модуль, который извлекал данные по определенной логике, приводил их к общему формату и складывал в базу. В базе данных хранилось и состояние модулей: активная работа, простой, ошибка, время последнего и следующего запуска, логи, настройки и прочее.
Результаты
Получившееся приложение не было требовательным к ресурсам сервера. Для его работы хватило виртуального сервера с 4 Гб ОЗУ, 4 ядрами и 20 Гб дискового пространства. Причем большая часть ресурсов была нужна для поддержки работы операционной системы. Запускали и мониторили приложение с помощью менеджера PM2.
Если поместить это приложение в существующий корпоративный кластер Kubernetes, можно было бы уменьшить вычислительные ресурсы. Но в данном проекте его не использовали.
Все собранные системой данные передавались для ручного и автоматизированного анализа с помощью ИИ, что впоследствии помогало строить прогнозы и тренды на рынке отрасли.

Прирост прибыли от анализа статистических данных рынка зависит от многих факторов, таких как точность данных, качество анализа, правильность принятых решений и т.д. Однако, в среднем, при правильном использовании таких данных и принятии соответствующих мер прогнозируемый прирост прибыли составляет от 5% до 20%.
Получившееся приложение не было требовательным к ресурсам сервера. Для его работы хватало виртуального сервера с 4 Гб ОЗУ, 4 ядрами и 20 Гб дискового пространства. Собранные данные впоследствии использовались для ручного анализа и передачи в системы анализа больших данных с помощью ИИ для построения прогнозов и трендов на рынке отрасли.
Интересное:




Новости отрасли:


Все новости:




Публикация компании
Профиль
Социальные сети