
Смогут ли тензорные процессоры конкурировать с решениями NVidia для ИИ
Какие альтернативы ушедшим зарубежным решениям существуют на сегодняшний день — рассказывает руководитель компании Statanly Technologies Сергей Федоров

Руководитель компании Statanly Technologies, а также исследовательского подразделения Statanly Research. За последние годы компанией были реализованы сотни проектов в области внедрения ИИ
Графические процессоры (GPU) являются общепризнанным стандартом для систем искусственного интеллекта. В марте 2022 года, компания Nvidia — мировой лидер производства графических процессоров приостановила официальные поставки своей продукции в России. Спустя несколько месяцев ряд крупных российских компаний заявил, что нехватка чипов Nvidia может существенно затормозить развитие ИИ. И хотя компания контролирует около 80% рынка графических процессоров, есть ряд более молодых конкурентов, готовых подорвать ее монополию. Летом 2022 года наша компания, как ведущий разработчик ИИ-решений, начала изучать возможные альтернативы устройствам компании Nvidia.
Главной задачей было найти высокопроизводительное решение, которое может выдерживать огромные нагрузки и обрабатывать одновременно сотни видеопотоков. Устройства, типа Raspberry и аналогов, а также Huawei Atlas 500 сразу отпали из-за крайне скромных вычислительных характеристик.
Одной из таких альтернатив являются тензорные процессоры — архитектура предложенная компанией Google в 2016 году для машинного обучения. Тензорные процессоры, производимые Google, широко используются внутри корпорации и не поставляются на внешний рынок. Компания предлагает свои вычислительные ресурсы в виде облачного сервиса, который также нельзя использовать в России. Но Google не единственный производитель тензорных процессоров. Разработкой TPU занимается ряд китайских корпораций. Мы обратили внимание на компанию Sophgo, которая первоначально была подразделением китайской корпорации Bitmain и выделилась в отдельную компанию в 2021 году.
Тензорные процессоры — архитектура, предназначенная специально для искусственного интеллекта и оптимизированная, как с вычислительной точки зрения, так и энергоэффективности. Приведем общий сравнительный анализ различных вычислительных устройств:
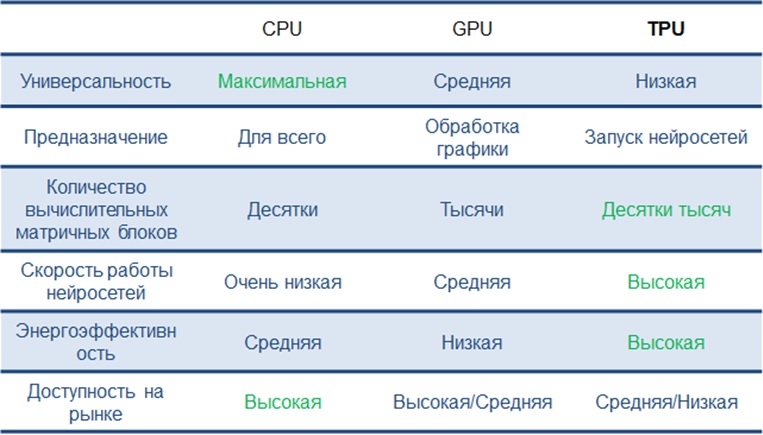
Сравнительный анализ производительности наиболее распространенных решений от Nvidia и Sophgo:
Производительность:
AI Micro Server SE6 ~ 211 TOPS (Int8)
Nvidia RTX 3090 ~ 35 TFOPS
Nvidia RTX 4070 ~ 29 TFOPS
Nvidia Tesla A100 ~ 624 TOPS (Int8)
AI Micro Server — 144Gb видеопамяти
Nvidia RTX 3090 — 24Gb видеопамяти
Tesla A100 — 80Gb видеопамяти
Количество видеопотоков:
AI Micro Server SE6 — 192 канала
Nvidia RTX 3090 — менее 36 каналов (проект «Умный город»)
Цена:
Tesla H100 ~ 4 млн. рублей
Tesla A100 ~ 2 млн. рублей
TPU (SE6-192) ~ 1 млн. рублей.
Анализ финансовых затрат для обработки требуемого числа видеоканалов моделью-детектором YoloV8n:
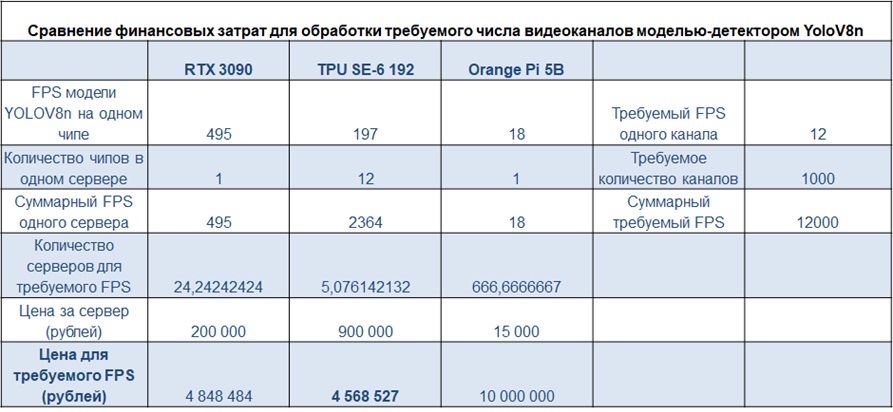
В итоге, из первичного сравнения TPU и GPU, можно отметить определенное преимущество решений от Sophgo, по меньшей мере на первый взгляд. Дополнительно отметим, были проведены десятки различных тестов нагрузки, одновременной обработки различного количества видеопотоков и FPS.
Перейдем теперь к трудностям и проблемам, с которыми мы столкнулись, адаптируя различные модели компьютерного зрения для работы на TPU. В качестве базового списка моделей мы взяли наши алгоритмы в рамках проекта умный город, около 20 моделей, типа распознания лиц, номеров, подсчета и трекинга объектов, детекции и сегментации. На сегодняшний день, официальная документация на сайтах Sophgo, на наш взгляд, кажется довольно сырой и непригодной для использования. Хотя заметны существенные изменения в сравнении с тем, что было год назад. Часто отсутствует необходимая техническая документация даже на английском языке (основная информация на китайском) и крайне мало примеров. Поэтому многие низкоуровневые компоненты пришлось реализовывать самостоятельно на C/C++.
В итоге, пройдя довольно непростой путь, мы достигли существенных результатов в создании полноценной SDK (инструментарий для построения конвейеров самых часто используемых задач компьютерного зрения, адаптированных на TPU) со множеством реальных примеров, а также полноценной документацией на русском языке. На текущий момент работы по адаптации новых алгоритмов продолжается. В частности, интересными будут задачи оптимизации больших языковых моделей (LLM) для TPU.
Интересное:




Новости отрасли:


Все новости:




Публикация компании
Достижения
Профиль
Социальные сети